Szóval, mielőtt lenne mit elemezni, előszöris le kell tölteni a forrásadatokat a torrent oldalról. Mint említettem az oldal zárt, ezért olyan scriptet kell használni a letöltéshez, ami képes autentikációt kezelni. Én erre a linuxos wget parancsot fogom használni. Tudom, hogy ez egy kicsit meglepő, valószínűleg sokan nem tudják, hogy micsoda potenciál lapul a wget-ben. Habár perl nyelven írom a scriptet, nem fogom az lwp könyvtárat használni, aminek az az oka, hogy az otthoni szerveremen (Dlink DNS-320), amin a programot futtatom, egy nagyon lebutított perl verzió van, amire az istennek sem sikerült ezt a modult felerőszakolnom. Így marad a wget.
Első lépés: bejelentkezés az oldalra, majd a cookie elmentése. Később e cookie segítségével tudunk hozzáférni az oldal adataihoz. Mint a login oldal forrásából látszik, itt egy egyszerű post-ról van szó: submittelni kell a felhasználói nevet (name=nev) és jelszót (name=pass) valamint jó ötletnek tűnik a csökkentett biztonság bekapcsolása, ami azt eredményezi, hogy nem kell minden alkalommal végrehajtani az autentikációt, amennyiben a cookie jelen van.
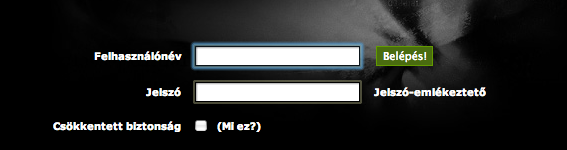
Ez a html forrásban valahogy így néz ki:
1
2
3
4
5
6
7
8
9
10
11
|
<div id="login">
<form method="post" action="login.php?honnan=/torrents.php" name="login" onsubmit="return liEllenorzes()">
<input type="hidden" name="set_lang" value="hu">
<input type="hidden" name="submitted" value="1">
<table>
<tr><td class="login_td">Felhasználónév</td><td><input tabindex=1 class="beviteliMezo" type="text" id="nev" name="nev"
<tr><td class="login_td">Jelszó</td><td><input tabindex=2 class="beviteliMezo" type="password" name="pass"
<tr><td class="login_td">Csökkentett biztonság</td><td><input tabindex=3 name="ne_leptessen_ki" type="checkbox" value="1">
</table>
</form>
</div>
|
A belépés és az autentikáció a következő wget parancs perl-be ágyazásával történt:
1
|
wget --user-agent="Mozilla/5.0 (Windows NT 5.2; rv:2.0.1) Gecko/20100101 Firefox/4.0.1" --save-cookies cookies.txt --post-data='nev=UserName&pass=Password&ne_leptessen_ki=1' -O - -o /dev/null http://torerntURL.hu/login.php
|
Itt azt érdemes észrevenni, hogy használunk egy user agent-et, ami kb elrejti a kérésünket egy fake böngésző mögé. Sok oldal nem szolgálja ki azokat a kéréseket, amik nem böngészőtől jönnek. Ezt egy másik oldallal kapcsolatos kalandom során vettem észre. Az elküldött adatok a post-data kapcsoló mögött vannak szépen URI szabály szerint: küldjük a felhasználói nevet, a jelszót, és szépen megkérjük az oldalt, hogy a session végén ne léptessen ki. A visszakapott cookie-t (surprise, surprise) a cookies.txt állományba mentjük. Erre fogunk a későbbiekben hivatkozni. A kavarás a végén azért kell, hogy a letöltött adatokat ne file-ba mentse, hanem a vágólapra: így a perl-ből hívott program output-ja egyből egy változóba kerül.
Második lépés: kilistázni a magyar és nemzetközi zenéket tartalmazó torrenteket (mp3 + flac). (Itt nem vesszük figyelembe a videoklippeket, amik viszonylag marginális részét képzik az össz zenei kínálatnak, de annyira egyszerű volt szűrni, hogy inkább kiszedtem.) Itt egy kb. 78 ezer elemű halmazunk van, amin 1oo-asával fogunk végigmenni. Itt ki fogjuk szedni az összes torrent azonosítóját, és egy listába mentjük. Szerencsére a perl regexp funkciója pompás, így ez gyerekjáték. Természetesen ehhez is wget-et használunk, illetve megadjuk a bejelentkezéshez az előbb letöltött cookie-t.
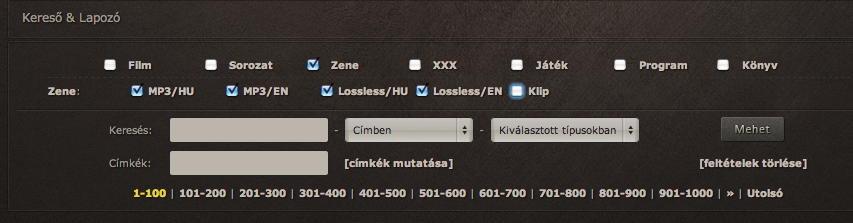
A böngészővel történő navigálással analóg módon, post-oljuk a kívánt paramétereket, és a visszatérő oldalból mentjük le a torrent azonosítókat. Ezt a lépést annyiszor kell megismételni, ahány oldalra kifér az összes torrent. Persze az oldal indexet növelni kell egészen a maximális értékig.
1
|
wget --load-cookies cookies.txt --post-data='oldal=1&tipus=kivalasztottak_kozott&kivalasztott_tipus=mp3_hun,mp3,lossless_hun,lossless'-O - -o /dev/null http://torerntURL.hu/torrents.php
|
A maximális indexet az "utolsó" oldalhoz tarozó indexként kapjuk meg a html forrásból:
1
|
<a href="/torrents.php?oldal=2516"><strong>Utolsó</strong></a></div>
|
A visszatérő oldal tartalmazza mindazt az adatot, amit akkor látnánk, ha böngészővel adtuk volna ki a parancsot. Tehát valami ilyesmit kapunk html forrásban:
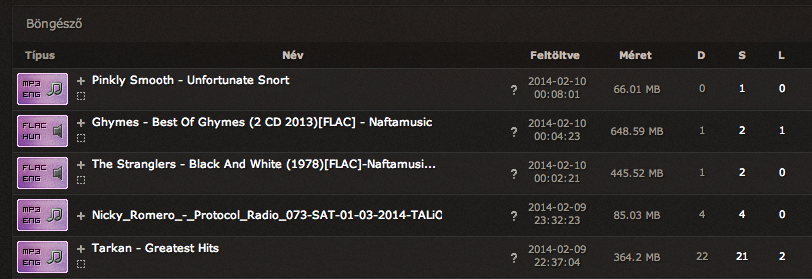
Itt már nagyon sokminden látszik, amit használni is fogunk: feltöltés ideje, letöltések száma (D), seederek száma (S) és a leecherek száma (L). (Látszik még a feltöltők neve, de azokra tojunk, nem vagyunk mi ASVA :) Ugyanakkor valami fontosat nem látunk: nem látjuk a tag-eket! A lényeghez rá kell kattintani a torrent nevére, és akkor jönnek elő a részletek egy lenyíló menüben.
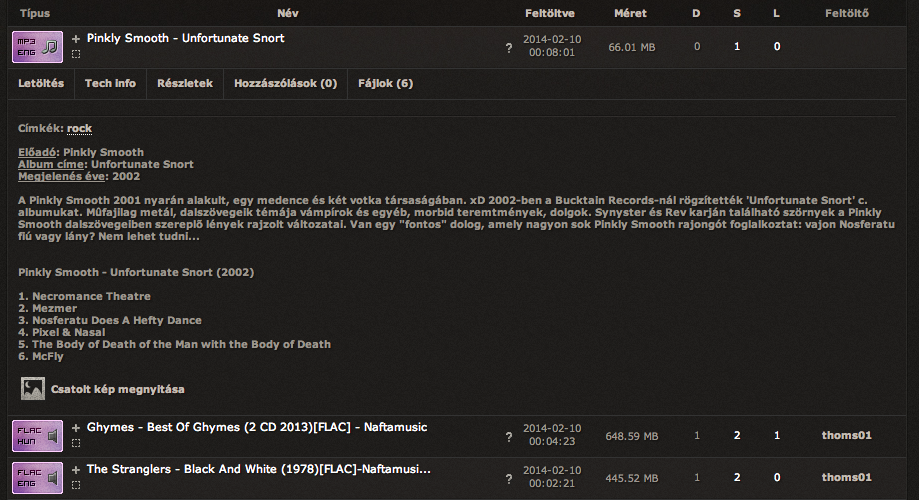
Sok egyéb dolog mellett már ott vannak a címkék is. Nagyszerű! Az a baj, hogy ezek az adatok nem az eredeti html-ben vannak, hanem a torrent nevére kattintva egy külön html hívás keretében töltődnek be. Ez nagyban lelassítja a forrásadatok letöltését, hiszen minden egyes torrent adatfile-ját le kell tölteni, és nem elég csak a lista oldalt. De nem baj, megoldjuk. Szóval egyelőre ott vagyunk a lista oldalon, és mit látunk: látjuk az összes torrent azonosítóját a html forrásban. Nosza, mentsük el!
1
2
|
<a href="torrents.php?action=details&id=1487535" onclick="torrent(1487535); return false;" title="Pinkly Smooth - Unfortunate Snort">
<nobr>Pinkly Smooth - Unfortunate Snort</nobr></a>
|
Szóval itt azt látjuk, hogy minden torrent neve előtt szerepel egy link a torrent azonosítójával (1487535). Ez az azonosítót vesszük ki és mentjük el egy file-ba. Én szeretek minden részfolyamatot külön script-tel intézni, nem vagyok híve a nagy integrált rendszereknek. Ez azt is lehetővé teszi, hogyha valahol elhasal a script, akkor könnyebb felvenni a fonalat és talán a hibakeresés, módosítás is egyszerűbb. Ok, akkor nekiállunk és letöltjük az azonosítókat. Következő alkalommal innen folytatjuk!
(BTW, a szintaxis kiemeléseket a http://hilite.me/ oldal segítségével oldottam meg. thx nekik.)
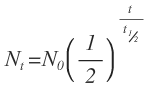 Ahol N0 a kiindulási elemszám, Nt az elemszám t idő múlva, és t1/2 a felezési idő. A képletet átrendezve kifejezhetjük a felezési időt:
Ahol N0 a kiindulási elemszám, Nt az elemszám t idő múlva, és t1/2 a felezési idő. A képletet átrendezve kifejezhetjük a felezési időt: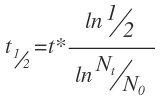 Ebbe behelyettesítve a felezési időnek kijön 491 nap. Nem is rossz! Szerintem ez igazán szép érték, ez azt jelenti, hogy ennyi idő alatt a feltöltött torrentek felét letörlik. A felezési időből kiszámolható a bomlási konstans (λ), és az átlagos életidő (τ):
Ebbe behelyettesítve a felezési időnek kijön 491 nap. Nem is rossz! Szerintem ez igazán szép érték, ez azt jelenti, hogy ennyi idő alatt a feltöltött torrentek felét letörlik. A felezési időből kiszámolható a bomlási konstans (λ), és az átlagos életidő (τ):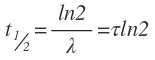 Az egyenlet átrendezésével azt kapjuk, hogy a zenei torrentek átlagos életideje kb 700 nap. Felmerülhet a kérdés: vajon ez azt jelenti, hogyha látok egy jó torrentet, akkor ráérek 2 évig a letöltéssel? NEM! Előfordulhat (kiszámítható valószínűséggel), hogy a torrent néhány hónap múlva már halott lesz! Persze az is, hogy akár több éven keresztül is akadnak seederek. Ez az érték egy átlagos életidőt jelent, ami egy sokaság vizsgálatával lett meghatározva.
Az egyenlet átrendezésével azt kapjuk, hogy a zenei torrentek átlagos életideje kb 700 nap. Felmerülhet a kérdés: vajon ez azt jelenti, hogyha látok egy jó torrentet, akkor ráérek 2 évig a letöltéssel? NEM! Előfordulhat (kiszámítható valószínűséggel), hogy a torrent néhány hónap múlva már halott lesz! Persze az is, hogy akár több éven keresztül is akadnak seederek. Ez az érték egy átlagos életidőt jelent, ami egy sokaság vizsgálatával lett meghatározva.